乱读天书, 不求甚解
周祎骏的个人云笔记
Toggle navigation
乱读天书, 不求甚解
主页
Linux:系统配置
Linux:用户管理
Linux:优化排错
Linux:进程调度
Linux:文件系统
Linux:网络
Linux:系统服务
Linux:安全
Linux:内核
容器:Docker
容器:containerd
容器编排:Kubernetes
IAC:Terraform
大数据:Hadoop
大数据:Zookeeper
大数据:Hbase
消息队列:rsyslog
消息队列:kafka
数据库:MySQL
数据库:MongoDB
搜索引擎:Elasticsearch
时序数据库:OpenTSDB
网站服务:Nginx
编程:Bash
编程:Perl
编程:Python
编程:C
编程:JAVA
编程:Rust
版本控制:gitlab
知识管理:docusaurus
常用小工具
关于我
标签
kafka 0.0 介绍
2017-03-29 13:35:23
86
0
0
admin
> kafka 是一款分布式,基于磁盘的消息队列 #kafka特点: kafka 是分布式的消息系统,支持partition 和 replica。 kafka 数据都会存在磁盘上,不会因为断电丢失;kafka 通过磁盘顺序读写以及buffer来提高性能。 kafka 不会因为下游取走数据就删除数据,kafka 有自己的删除数据的机制(保持某段时间内的数据或者保持多少kb 数据)。 kafka 的一个队列可以有多个下游,由下游的客户端自己管理offset。 *** #kafka的结构,概念 *图片来自kafka官网* 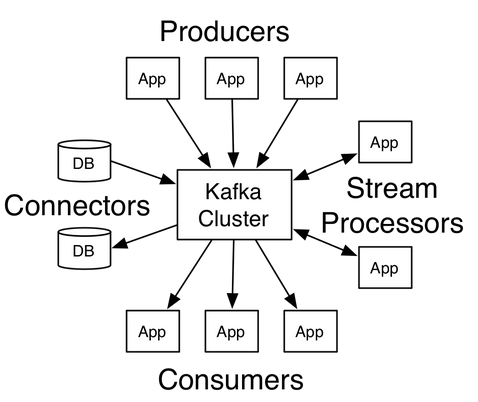 **各种实例:** **producer**:消息生产者,就是把消息发给kafka的家伙。 **consumer**:消息接收者,就是从kafka中取数据的家伙。 **broker**:通常指kafka实例。 **stream**:新东西,可以写一些处理数据的逻辑,类似于storm/spark。存在的意义是:如果你需要做一些简单的处理,但是你不想专门去搞一个storm/spark 这种集群的话,可以用kafka 自带的这个功能。 **connector**:新东西,帮kafka将数据导入或者导出到其他地方的工具。 *** **各种概念:** **topic**:一个队列的名字。 **offset**:相当于数据的序号或者位置,一般由consumer自己维护。 **partition**:一个topic可以分成多份放在不同的broker中,做到分布式。数据在partition中是先进先出的,但是如果一个topic有多个partition,它的数据在topic层面上不是先进先出,因为可能有的partition快,有的partition慢。要做到topic层面的先进先出,就只能有一个partition。 **replica**:一个topic可以有多个备份,做到高可用。 **leader**:一个topic的某一个partition只有一个leader实例,所有对该partition 的读写都是通过这个leader的。 **follower**:一个partition可以有多个follower实例(其实就是replica)。follower的实现就是leader的 consumer。那些与leader保持完全同步的follower被称为ISR,当leader宕机的时候,ISR会被选为新的leader。 **controller**:相当于kafka集群的master,负责leader选举(就它说了算)和一些其它的工作,controller宕机集群会通过zookeeper选举新的controller(这次是真的选举) *图片来自官网* 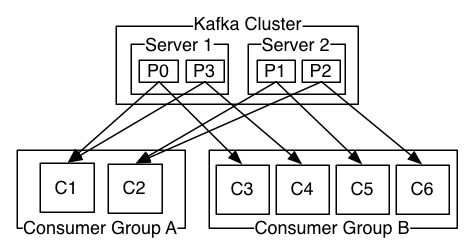 **consumer group**:多个consumer可以组成一个consumer group, 一个consumer group 中,对于某一个topic 的某一个partition只能有一个consumer。consumer对partition可以一对多。(一个group 可以理解成一个消费该队列的业务,该group下的consumer都是服务于该业务的。多个consumer相当于负载均衡。如果多个consumer读取同一个partition会有一些难以处理的事情,所以禁止这样做) *** **设计特点:** **磁盘顺序读写**:所有的数据按照offset的顺序存入磁盘,读的时候也可以按照这个顺序读。这种方式比随机读写的方式效率很多(减少磁盘寻址)。注:这个顺序读写指的其实是在文件系统上顺序读写,并不是在磁盘上顺序读写。磁盘读写由文件系统控制,不过即使是这样,性能提升也是显著的。 **不维护offset,不删除已消费的数据**:数据消费后不删除,由各个consumer自己维护offset,这样一个队列就可以由多个业务同时使用。事实上,因为数据是顺序读写的,consumer仅需要告诉kafka我要的数据的offset以及我要多少数据,kafka就直接把offset所对应的文件的地址一直到consumer要的最后一条数据所对应的文件地址的中间的那些文件数据直接发给consumer,类似scp。是不是很流氓? **zero copy**:更流氓的来了,由于数据是不加任何处理就直接发给consumer的,所以也就无需kafka来处理。kafka使用了zero copy 技术,让内核直接把数据发给consumer。(通常是是内核从磁盘把数据读出来,交给程序,程序处理好再交给内核,内核再交给网卡,中间数据一次从内核态copy到用户态,一次从用户态copy到内核态,对于kafka来说是不必要的。可以说比scp 都高效率了。。。。) *注:如果kafka升级到了高版本,consumer没有升级,且两者数据格式不一样的话,kafka会把数据翻译成低版本,这时候就不能zero copy了。* **利用pagecache**:kafka不会一有数据就写磁盘,它会写到Linux的 cache 中,由系统来控制什么时候写磁盘,这样减少了频繁的读写,提高效率。
上一篇:
hadoop 1.01 如何增加/去除节点
下一篇:
kafka 1.0 安装
文档导航
