乱读天书, 不求甚解
周祎骏的个人云笔记
Toggle navigation
乱读天书, 不求甚解
主页
Linux:系统配置
Linux:用户管理
Linux:优化排错
Linux:进程调度
Linux:文件系统
Linux:网络
Linux:系统服务
Linux:安全
Linux:内核
容器:Docker
容器:containerd
容器编排:Kubernetes
IAC:Terraform
大数据:Hadoop
大数据:Zookeeper
大数据:Hbase
消息队列:rsyslog
消息队列:kafka
数据库:MySQL
数据库:MongoDB
搜索引擎:Elasticsearch
时序数据库:OpenTSDB
网站服务:Nginx
编程:Bash
编程:Perl
编程:Python
编程:C
编程:JAVA
编程:Rust
版本控制:gitlab
知识管理:docusaurus
常用小工具
关于我
标签
Mongodb 1.70 aggregation
2017-09-10 08:19:40
77
0
0
admin
> 聚合,就是对搜索出来的数据再做一些计算或者统计 #聚合管道 *图片来自官网* 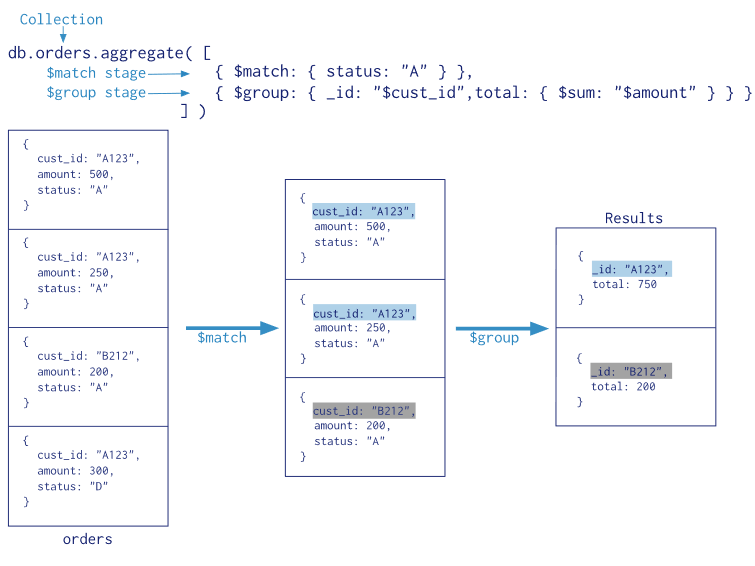 #一些聚合 * \$match 只对满足条件的数据做操作 ``` {$match:{b:23}} ``` * \$project 只获取想要的field,同时可以给field改名 ``` {$project:{"lala":"$a","a":1,"_id":0}} //把 a 的field名改成 lala,显示 a,不显示 _id ``` * \$group 以及\$sum \$avg \$min \$max 将搜索结果分组 总数,平均值,最大最小 ``` > db.a.aggregate([ {$group:{_id:"$a","total":{$sum:"$b"}}} ]) //根据field "a" 分组,再计算每个组的field "b" 的和 ``` * \$unwind 将数组拆分成多个文档 ``` > db.a.find({"z":{"$exists":true}}) { "_id" : ObjectId("59b5243582f196305a9db951"), "z" : [ 1, 2, 3, 4, 5 ] } > db.a.aggregate({"$unwind":"$z"}) { "_id" : ObjectId("59b5243582f196305a9db951"), "z" : 1 } { "_id" : ObjectId("59b5243582f196305a9db951"), "z" : 2 } { "_id" : ObjectId("59b5243582f196305a9db951"), "z" : 3 } { "_id" : ObjectId("59b5243582f196305a9db951"), "z" : 4 } { "_id" : ObjectId("59b5243582f196305a9db951"), "z" : 5 } ```
上一篇:
Mongodb 1.60 explain
下一篇:
Mongodb 1.90 使用上的一些心得
文档导航
